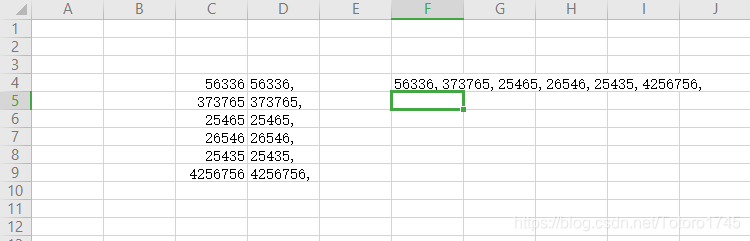
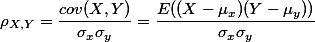前言
在之前的经历里遇到一些需要确定各部分权重来得出最终结果的问题,例如用户游戏偏好得分的计算、用户价值模型的构建以及贡献度的计算等,所以这篇博客就讲讲如何确定权重~
权重计算方法
权重是指某因素在整体评价中的相对重要程度。权重越高,则该因素越重要。权重有两个特点:
- 每个因素的权重在0-1之间
- 所有因素的权重和为1
权重的确定方法有很多,主要分为以下两大类:
| 主观赋权法 | 客观赋权法 | |
|---|---|---|
| 思路与优缺点 | 由专家根据经验进行主观判断得到权数,然后对指标进行综合评价。这是一种定性方法,易操作,但主观性强 | 根据历史数据研究指标之间的相关关系或指标与评估 结果的关系来进行综合评价。这是定量研究, 没有考虑决策者的主观意愿和业务经验,同时计算方法较繁琐 |
| 常用方法 | 层次分析法 | 主成分分析法(或因子分析法) |
| 其他方法 | 权值因子判断表法、德尔菲法、模糊分析法、二项系数法、环比评分法、最小平方法、序关系分析法 | 变异系数法、最大熵计数法、均方差法、神经网络、回归分析法等 |
常用方法
这里就简单说下两种方法:层次分析法和变异系数法
1.层次分析法
层次分析法简称AHP,是指将与整体决策有关的元素分解成目标、准则、方案等层次,然后进行定性和定量分析的方法。根据总的目标,可以将问题分解为不同的因素